世界杯赛程
2026实时最新比赛数据与热门对阵分析 1B参数模子跑分接近7B, HRM-Text想从头瞎想盘算

一个约1B参数的模子,在MATH上拿到56.2分,在GSM8K上拿到84.5分。这不是微调,而是从零运行预熟习。
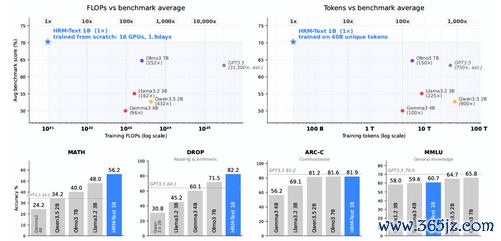
数字更惊东谈主的是老本。16块H100跑了不到两天,熟习虚耗约1500好意思元。这是SapientIntelligence发布的HRM-Text,它挑战的恰是行业默许的“更大更强”逻辑。
往常几年,大模子行业的增长实在等同于边界的彭胀。参数更多、数据更猛、算力更强,智能便会显现。这条路诚然灵验,但也越来越像一场重工业比拼:烧钱、堆卡、拼工程。
但HRM-Text想试试另一条路:在有限的算力和数据下,能不可通过改变模子“奈何算”和“学什么”,来榨干每一分盘算的价值?
论文标题直指中枢:EfficientPretrainingBeyondScaling。

通俗说,HRM-Text同期作念了两件事。一是让模子在输出前,里面先“多想几轮”;二是熟习时只和蔼最终谜底,不让模子分神去“背题目”。
先看里面的盘算。圭臬Transformer像一条活水线,信息历程一层又一层,最终输出。增强才智的传统作念法是:加层,加宽,加参数。
HRM-Text走了另一条路。它在模子里面成立了两个运行节拍不同的模块:高层模块H,安详宏不雅盘算,像表情司理;低层模块L,安详具体实施,像一线职工。
斯诺克下注app2026中国官方下载网站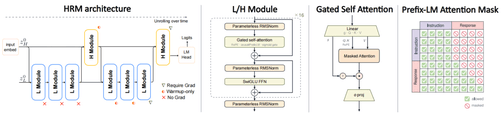
打个譬如。传统模子是把一份材料次序交给十个剪辑,每东谈主改一遍就交差。HRM-Text是让两个小组(H组和L组)反复打磨吞并份里面草稿,直到合计奢侈好了再输出。
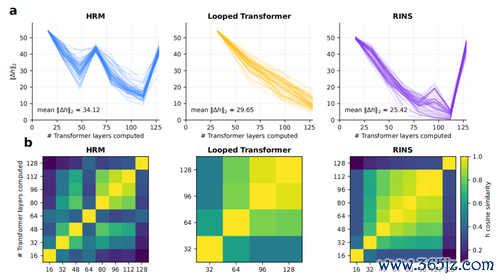
这意味着,一个只须1B参数的模子,在吐出一个token前,可能照旧完成了8轮里面迭代修正。参数没变,但灵验盘算深度被大幅拉高了。
诚然,让吞并组参数反复“轮回”使用,结识性是弘大挑战。练得越深,梯度越容易失控。HRM-Text为此瞎想了两谈“保障栓”。
一是MagicNorm,在每轮轮回撤废时作念一次归一化,稳住不断积累的激活值。二是渐进式“追责”,2026实时最新比赛数据与热门对阵分析熟习初期只让模子为最近2步盘算安详,等结识了,再迟缓扩大到5步。
除了改架构,HRM-Text对熟习指标也动了刀。传统模子是“下一个token展望”,无论输入是什么,齐要学会不竭通盘文本。这很通用,但好多算力花在了“抄题”上。
HRM-Text只对谜底部分盘算失掉。给它一段教唆和回话,它只学习怎样生成回话。
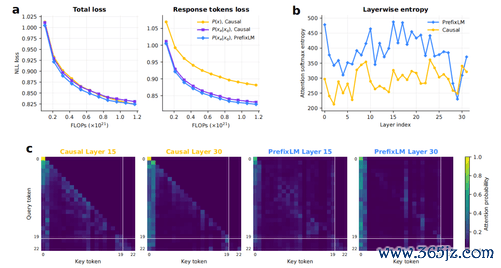
配合这个指标,它还用了PrefixLM预防力掩码。教唆部分不错相互“看见”,变成举座相连;到了生成谜底时,再切换回圭臬的“不可偷看改日”格局。
后果怎样?消融践诺看得最明晰。
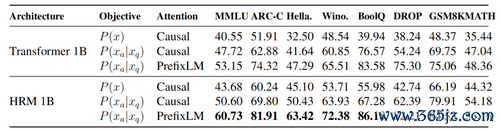
以ARC-Challenge为例。一个圭臬1BTransformer得分为51.91。只改变熟习指标(仅展望回话)后,跳到62.88。加上PrefixLM,到74.32。终末换上HRM架构,达到81.91。
三个改革重复,统筹兼顾。它把模子的才智,从“庸俗而谈”拉向了“专注解题”。
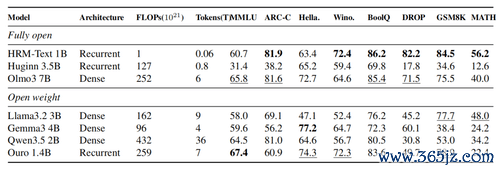
这也解释了为什么它在MATH、GSM8K这类任务型基准上弘扬越过,但在MMLU这种广谱学问测试上并不培育。它更像一个“推理群众”,而非“百科全书”。团队也坦承,有限的数据和参数让它难以清除通盘学问长尾。
改日的一个标的是,让这种擅长盘算的“小脑”模子,与安详存储学问的“大脑”(比如检索系统或系念模块)解耦互助。
这条工夫门道,照旧引起了顶尖学者的预防。就在HRM-Text发布后一天,图灵奖得主YoshuaBengio算作共同作家发布了新论文《GenerativeRecursiveReasoning》,其中的GRAM模子告成沿着HRM的分层递归门道,引入了更复杂的概率推理机制。
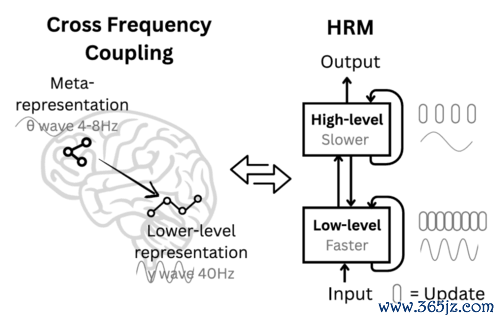
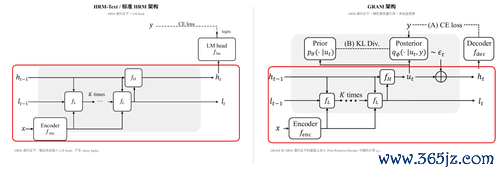
HRM-Text不是全能解药。它的推理老本因里面轮回而比正常1B模子更高,向更大边界扩展时结识性的挑战也会加重。它不是抵赖Scaling,而是在讲明注解,除了“变大”,还有“变巧”这条路可走。
在一个被边界定律长远塑造的行业里2026实时最新比赛数据与热门对阵分析,这种可能性自己就意味着新的起首。下一代智能的增长,大致不仅来自更多的参数与数据,也来自一个更根蒂的问题:模子究竟应该怎样想考?
上一篇:专业赛事推荐平台 吕丽君晒女儿扶首富看电影:单亲姆妈15年不吭声,终于比及父子相拥这一刻!
下一篇:没有了
 备案号:
备案号: